1. Neural Operators Accelerating Science: 2022 was an excellent year for neural operators, on the heels of being featured as a highlight in Math and Computer Science by Quanta Magazine in 2021. Neural operator learns mappings between function spaces, which makes them discretization-invariant, meaning they can work on any discretization of inputs and converge to a limit upon mesh refinement. Once the neural operators are trained, they can be evaluated at any resolution without re-training. In contrast, standard neural networks severely degrade in performance when the resolution of test data is different from that of training. In addition, we have extended it to a physics-informed neural operator that can exploit both data and physical laws and constraints for reducing modeling errors and enabling effective generalization.
We developed and deployed neural operators for a range of scientific domains. Neural operators have now accelerated carbon capture and storage (CCS) modeling and weather forecasting: 4-5 orders of magnitude faster while maintaining the same fidelity as numerical methods. These are immensely important for dealing with climate change. This speed enables the creation of ensembles with thousands of members, leading to improved uncertainty quantification.
We also employed neural operators for inverse problems, such as mask optimization in lithography. Inverse problems with traditional solvers require many iterations of the forward model, while neural operators require only one evaluation due to their differentiability. We extended neural operators to incorporate arbitrary geometries and used them for the inverse design of airfoils with ~100,000x speedup. We also used the neural operator to learn the long-term behavior of chaotic systems. Chaotic systems are inherently unpredictable since small changes in initial conditions lead to diverging trajectories. However, in many popular systems, such as fluid flows, reproducible statistical properties, such as energy spectrum and auto-correlation, exist over long-term trajectories. We used the neural operator to learn the transition kernel of chaotic systems and used the dissipative loss to stabilize the evolution while being able to recover the invariant statistical measure successfully.
2. Digital Biology: In 2021, our AI algorithms enabled an unprecedented understanding of the coronavirus. We used AI methods to model aerosolized coronavirus and deployed an unprecedented billion-atom system, one of the largest biochemical systems ever modeled at the atomic level. Our speedup of quantum-mechanical calculations using AI methods enabled this large-scale biological simulation for the first time. We also used neural operators to model the replication dynamics of the coronavirus as it invades the cells in a host. Both these papers were recognized as finalists for the Association for Computing Machinery (ACM) Gordon Bell Special Prize for Covid Research in 2021.
Continuing the streak, this year, we trained the largest biological foundation model for genome-scale modeling of the coronavirus with the ability to predict new variants of concern. We won the 2022 ACM Gordon Bell Special Prize for HPC-Based COVID-19 Research. Previously, variants of concern needed to be identified by individually going through every protein and mapping each mutation to see if any mutations were of interest, which is labor and time intensive. Our model makes this much cheaper and faster, allowing us to be more agile in dealing with current and future pandemics. As seen in the figure below, our diffusion-based hierarchical model we developed has better generation. (Fig.A) Comparison of statistics measured on generated sequences and on real data. (Fig. B) Generated sequences (light blue) from the model overlaid on the phylogenetic tree.

We developed large-scale foundation models for molecular understanding. Our retrieval-based molecular generative model adapts to new design criteria flexibly. It uses a small set of exemplar molecules that may only partially meet the design objectives and fuses this information with pre-trained molecular generative models to generalize to new tasks in a zero-shot manner. We optimize the binding affinity of eight existing, weakly-binding drugs for COVID-19 treatment under multiple design criteria. We also developed dynamic protein-ligand structure prediction with multiscale diffusion models and applied it to systems where the presence of ligands significantly alters protein-folding landscapes. We also developed multi-modal models by jointly learning molecules’ chemical structures and textual descriptions via a contrastive learning strategy. This enables challenging zero-shot tasks based on textual instructions such as structure-text retrieval and molecule editing.
3. Closing the Decision-Making Loop with Generalist AI Agents: 2022 was a breakthrough year for generalist AI where flexible transformer architectures can solve diverse tasks. We focused on using pre-trained foundation models for open-ended decision-making. Traditionally, reinforcement learning has focused on a single objective function and relied on billions of iterations, which makes it infeasible to adapt quickly to new open-ended tasks. We built the Minedojo framework in a Minecraft environment that can take text instructions for open-ended tasks using internet-scale knowledge of videos, wiki, and text information to train multi-modal models to aid fast reinforcement learning. It was recognized as an outstanding paper at NeurIPS 2022. We also built the VIMA benchmark for diverse robotic tasks.
4. Generative AI Unleashing Creativity: 2022 was the year of diffusion models enabling large-scale text-to-image generation. However, one downside of diffusion models is that it is still very slow to sample. For instance, when I used the Lensa AI app to generate personalized images, it took hours. On the other hand, many practical applications like robotics or autonomous driving would need faster than real-time generation. The reason diffusion models are slow is their need to simulate trajectories of the diffusion process from easy-to-sample distributions, such as the Gaussian distribution, and gradually transform it to the distribution of interest, such as natural images. These trajectories can be described by Ordinary Differential Equations (ODE). Using neural network surrogates such as neural operators to replace ODE solvers can significantly speed up sampling diffusion models, as seen in our recent work. We show that just one function evaluation. is sufficient to achieve the best image generation quality. In contrast, standard diffusion models require hundreds to thousands of evaluations to generate high-quality images.
5. Robust Vision and Video Understanding: We showed generative models improve the performance of downstream tasks, e.g., by enhancing robustness through denoising. We also developed robust vision transformer architecture, fully attention networks (FAN), with channel-based attention for robustness. We won the Semantic Segmentation Tracking of Robust Vision Challenge at ECCV. We adopted the SegFormer head on a pre-trained FAN model. We created the first large-scale radiance field dataset for perception, PeRFception, which consists of object-centric and scene-centric scans for classification and segmentation. It shows a significant memory compression rate from the original dataset while containing both 2D and 3D information in a unified form. We also developed a minimalist video segmentation architecture that outperforms on challenging occluded object benchmarks. It uses only frame-based training and does not rely on any specialized video architectures or training procedures.
6. Optimization: We developed the first fully deterministic weight initialization procedure for training any neural network. Neural networks are usually initialized with random weights, with adequately selected initial variance to ensure stable signal propagation during training. However, selecting the appropriate variance becomes challenging, especially as the number of layers grows. Our scheme, ZerO, initializes networks’ weights with only zeros and ones based on identity and Hadamard transforms. ZerO achieves state-of-art accuracy and can train ultra-deep networks without batch normalization, has low-rank learning trajectories that result in low-rank and sparse solutions, and improves training reproducibility.
7. Trustworthy AI: At NVIDIA, we enabled and enhanced model cards to enhance transparency and accountability. We augmented the original model card with model-specific information concerning bias, explainability, privacy, safety, and security. We also explored the limits of detoxifying large language models using self-generated inputs filtered for toxicity. We also developed efficient active and transfer learning methods for pre-trained language models without fine-tuning. Labeling for custom dimensions of toxicity and social bias is challenging and labor-intensive. We propose an Active Transfer Few-shot Instructions (ATF) approach, which leverages the internal linguistic knowledge of pre-trained language models to facilitate the transfer of information from existing pre-labeled datasets with minimum labeling effort on unlabeled target data.
8. Surgical AI: This involves assessing the skill of surgeons predicting patient outcomes, and discovering novel surgeon biomarkers based on multi-modal data and deep learning algorithms. The modalities are also diverse and can include video and audio of live surgical cases, as well as virtual reality, and the kinematics from a surgical robot. We developed surgical gestures as a building block of surgery and AI methods based on gesture sequences to predict 12-month functional outcomes after surgery. We also showed how real-time feedback significantly enhances surgical performance.
9. Team Accomplishments and Partnerships: I am incredibly blessed to be surrounded by amazing people at Caltech and NVIDIA, as well as collaborators in many other institutions. Zhuoran Qiao successfully defended in December 2022 and has been a leading force in AI for chemistry. Zongyi Li won the NVIDIA fellowship, as well as the PIMCO fellowship, along with Pan Xu. At Caltech, we initiated research partnerships with TII and Activision. My former student, Furong Huang, was recognized by MIT Technology Review as an Under 35 Asia Pacific 2022 Honoree.
10. Personal Triumphs: I was honored to be hosted by Prof. Terence Tao at UCLA as a distinguished speaker. I was also so happy to be featured on the Quanta (pic below) and AAAS websites. Our documentary 10kCasts was a Webby Award Honoree.

And perhaps the most important of all, I was so happy to celebrate my wedding to my soulmate Benedikt Jenik at the Caltech Athenaeum, surrounded by friends and family and officiated by my role model Frances Arnold.












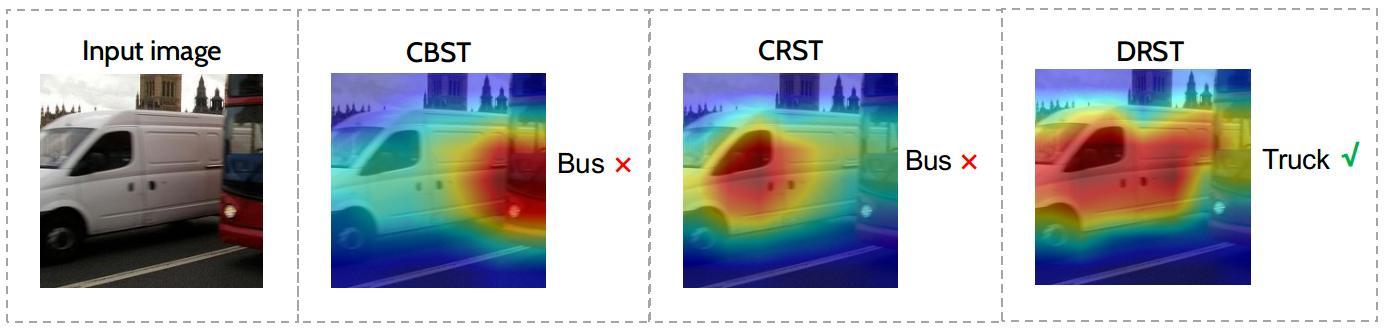 Saliency map for model (DRST) compared to baselines for self-training.
Saliency map for model (DRST) compared to baselines for self-training. Density ratio of source to target. A lower density ratio indicates a lower confidence.
Density ratio of source to target. A lower density ratio indicates a lower confidence.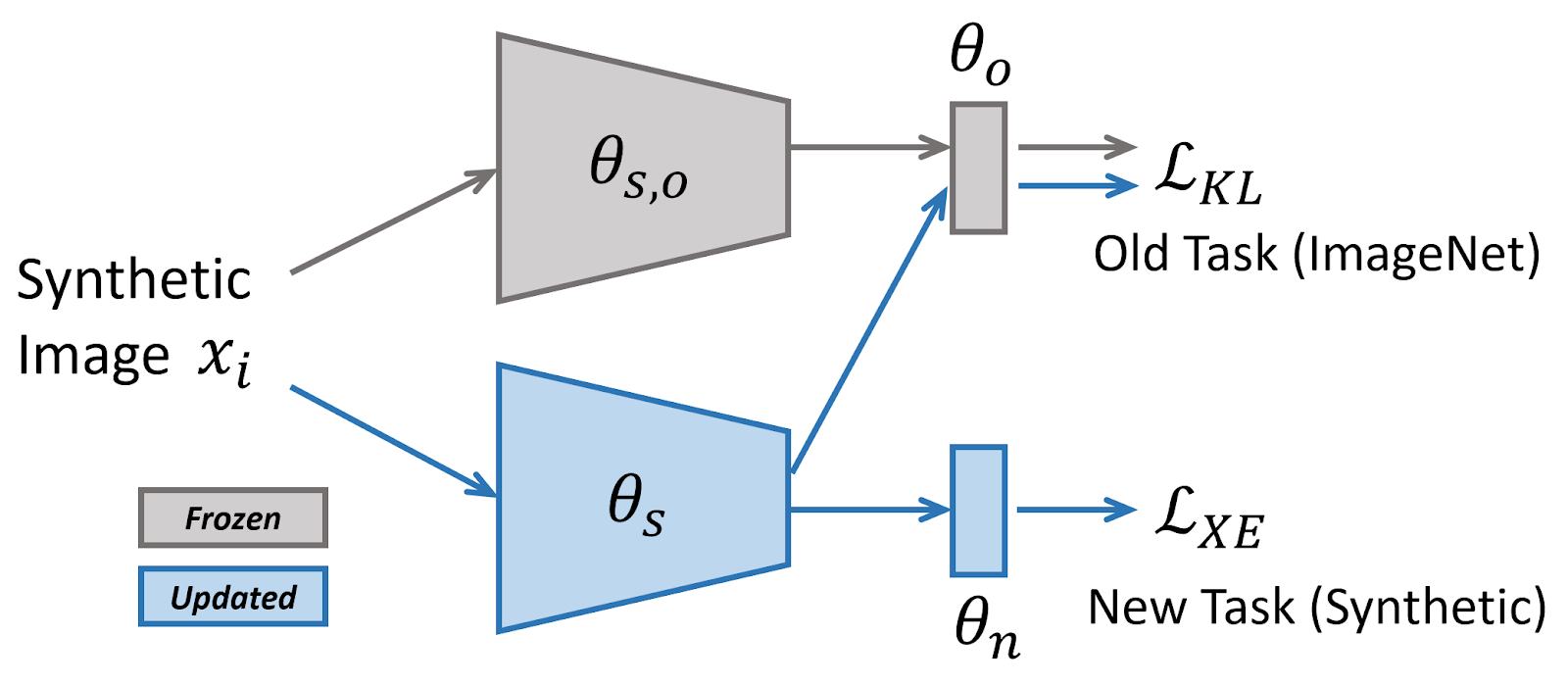
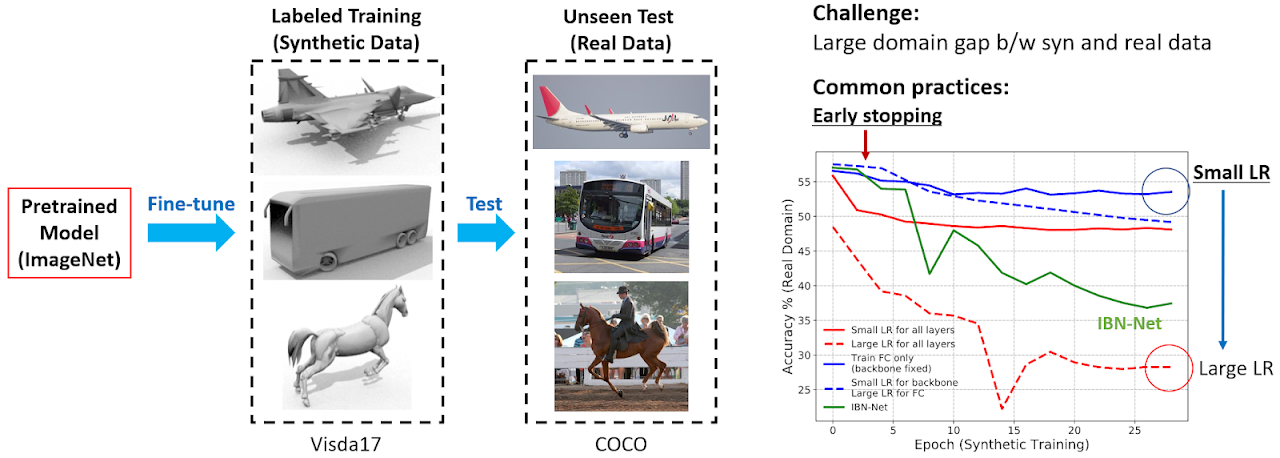
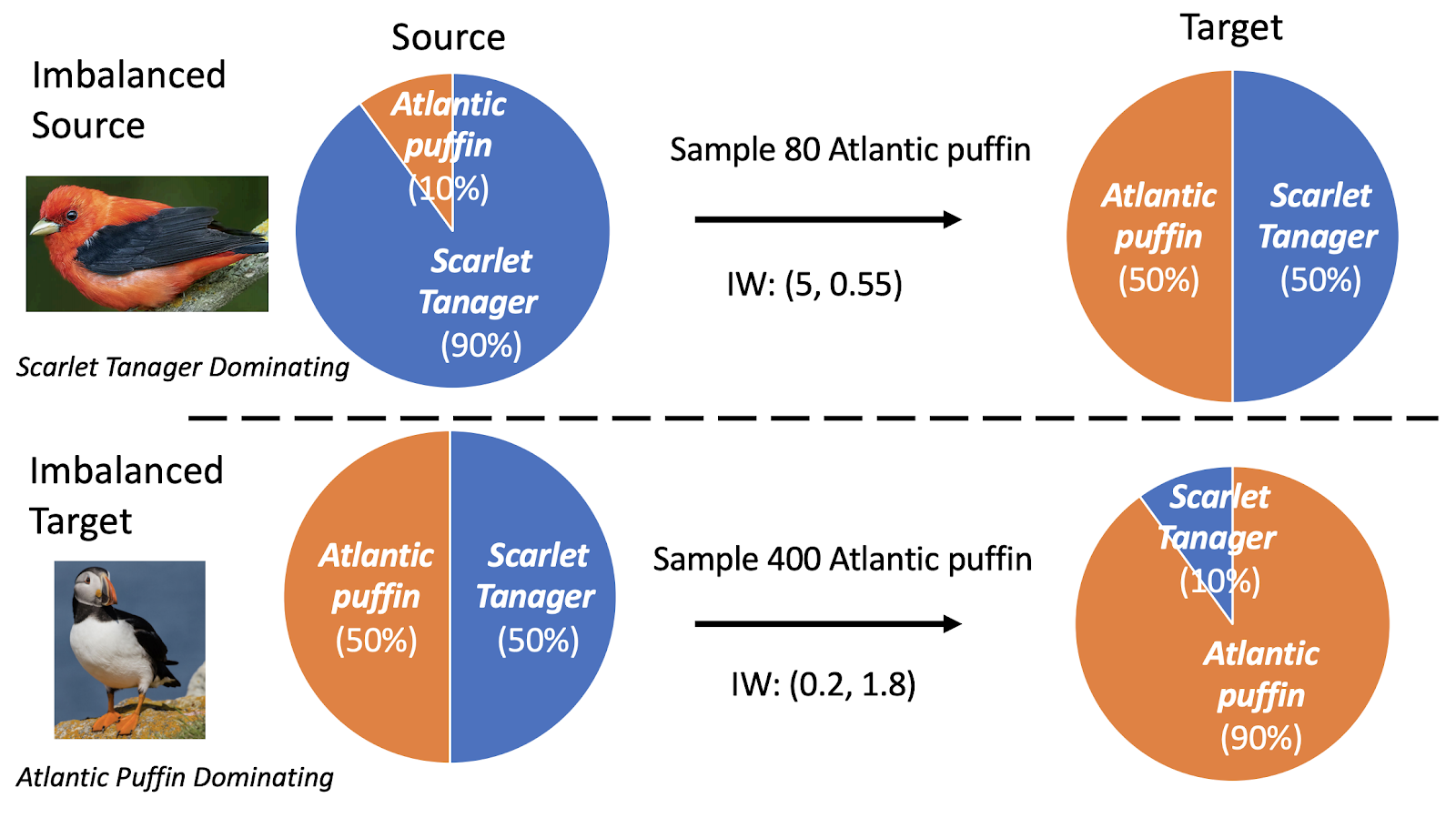
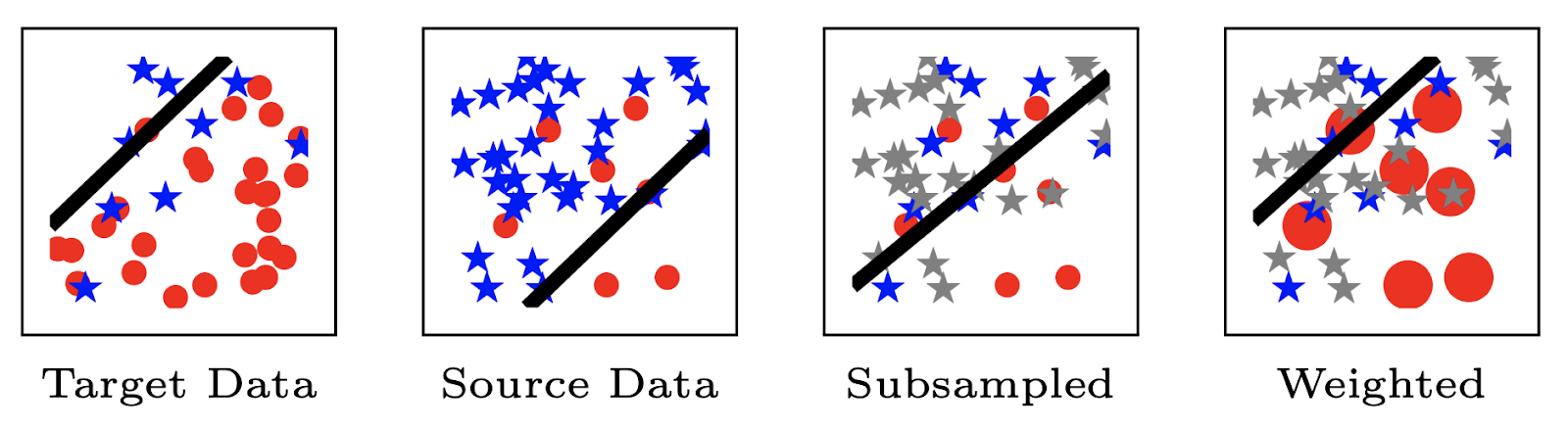
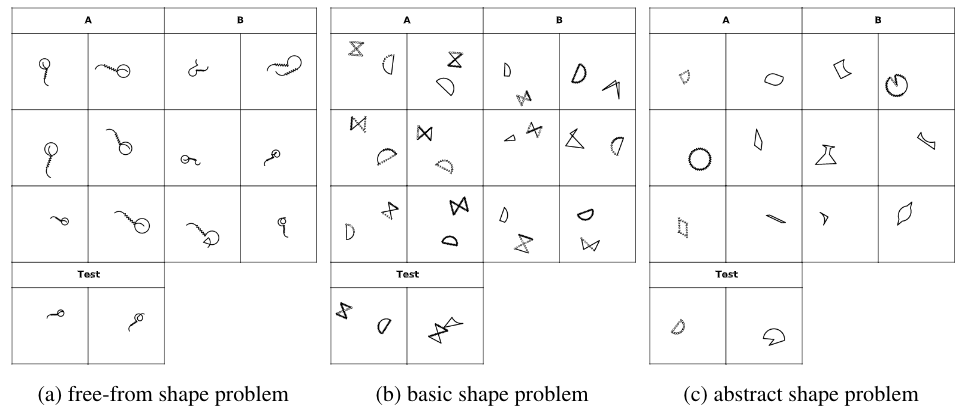

You must be logged in to post a comment.