Distributional shifts are common in real-world problems, e.g. often simulation data is used to train in data-limited domains. Standard neural networks cannot handle such large domain shifts. They also lack uncertainty quantification: they tend to be overconfident when they make errors.
You can read previous posts for other research highlights: generalizable AI (part 1), optimization (part 3), AI4science (part 4), controllable generation (part 5), learning and control (part 6), learning framework (part 7).
A common approach for unsupervised domain adaptation is self training. Here, the model trained on source domain is fine-tuned on the target samples using self-generated labels (and hence, the name). Accurate uncertainty quantification (UQ) is critical here: we should only be selecting target labels with high confidence for self training. Otherwise it will lead to catastrophic failure.
We propose a distributionally robust learning (DRL) framework for accurate UQ. It is an adversarial risk minimization framework that leads to a joint training with an additional neural network – a density ratio estimator. This is obtained through a discriminative network that classifies the source and target domains. The density-ratio estimator prevents the model from being overconfident on target inputs far away from the source domain. We see significantly better calibration and improvement in domain adaptation on VisDA-17. Paper
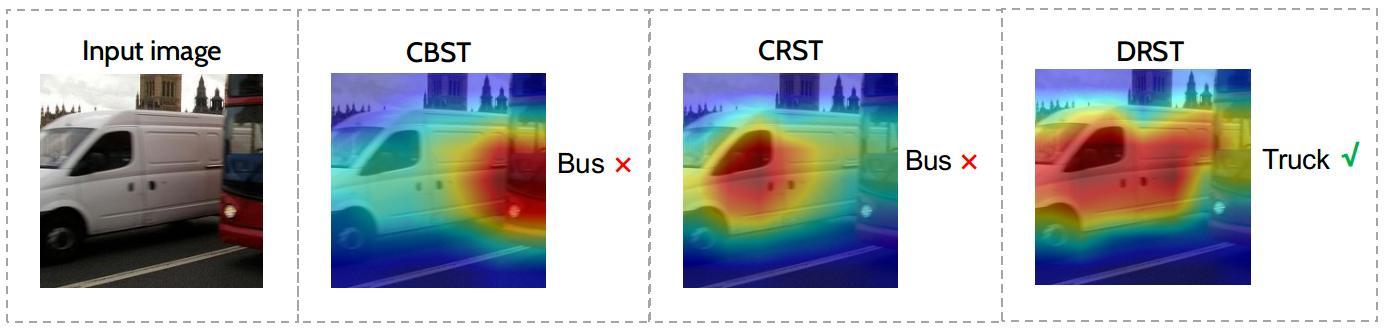

In a previous project, we proposed another simple measure hardness of samples, termed as angular visual hardness (AVH). This score that does not need any additional computation or model capacity. We saw improved self-training performance compared to baseline softmax score for confidence. Project
Another key ingredient for improved synthetic-to-real generalization involves domain distillation and automated layer-wise learning rates. We propose an Automated Synthetic-to-real Generalization (ASG) framework by formulating it as a lifelong learning problem with a pre-trained model on real images (e.g. Imagenet). Since it does not require any extra training loop other than synthetic training, it can be conveniently used as a drop-in module to many applications involving synthetic training. Project
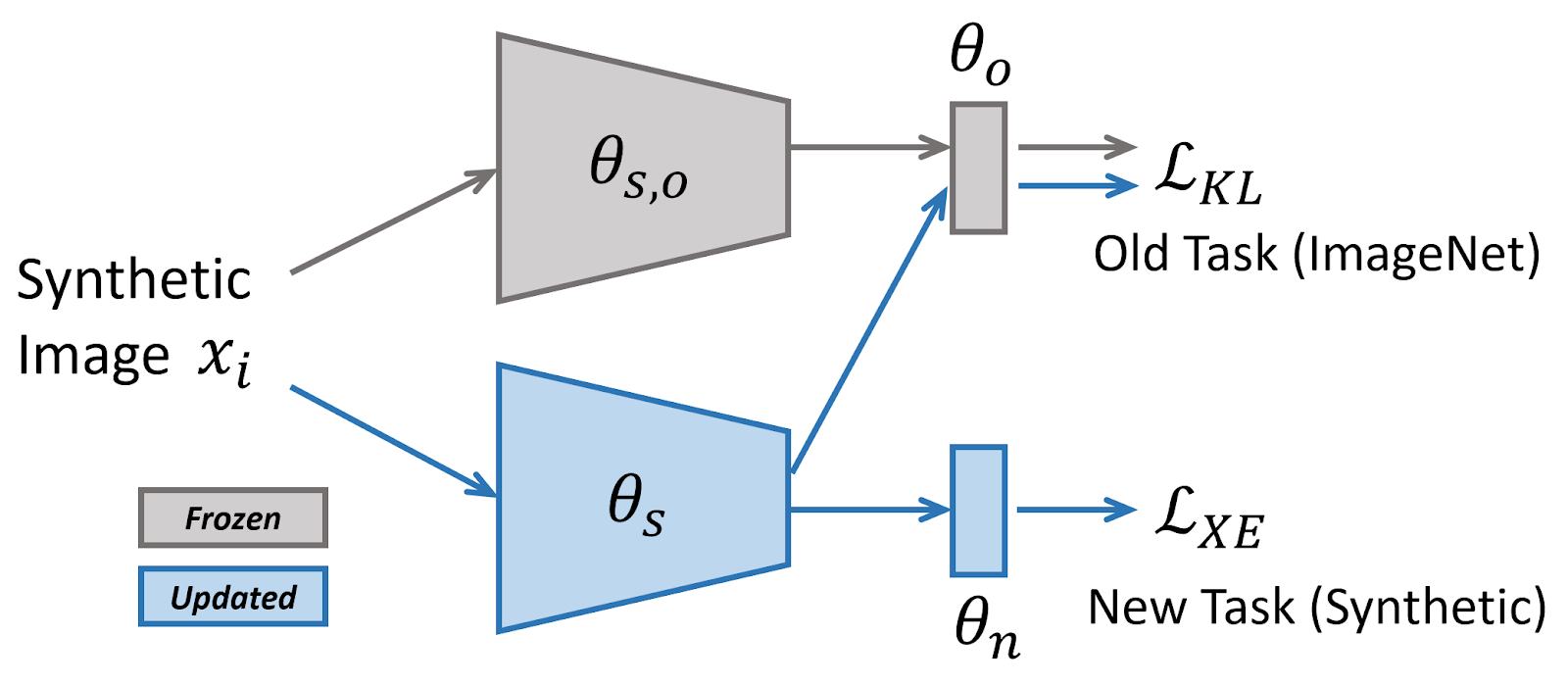
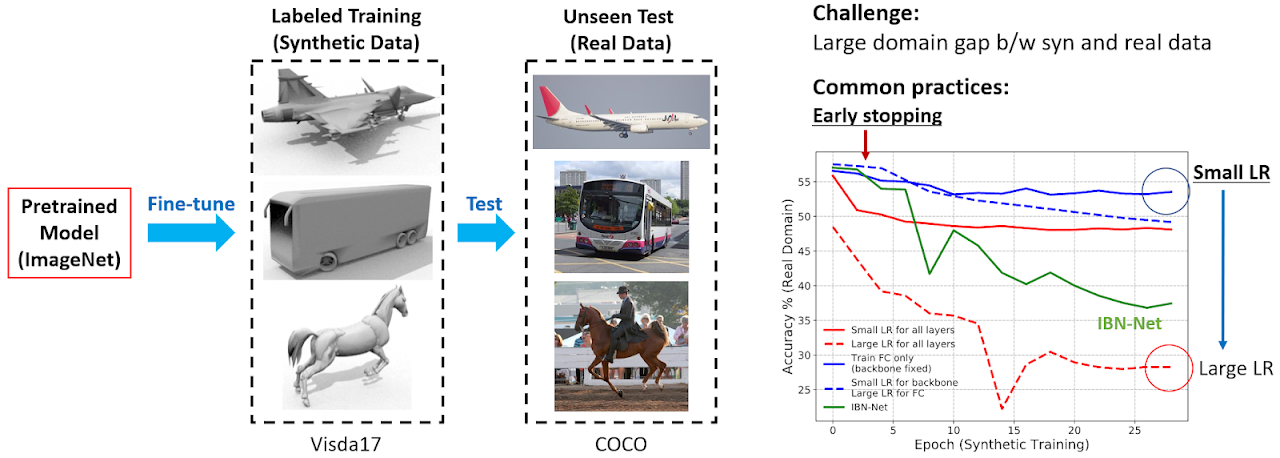
Combining ASG with density-ratio estimator yields state-of-art results on unsupervised domain adaptation. Paper
Fair ML: Handling Imbalanced Datasets
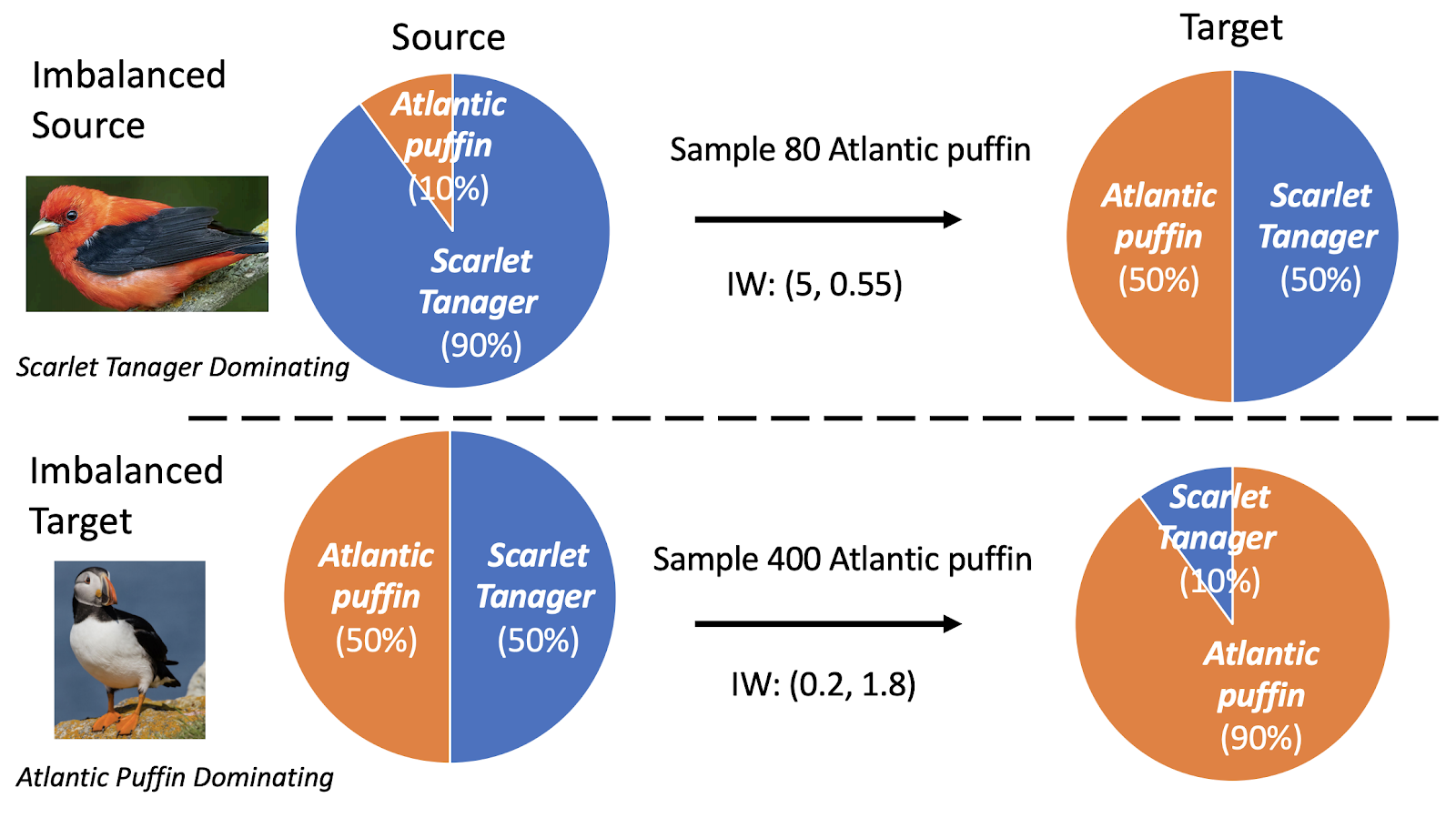
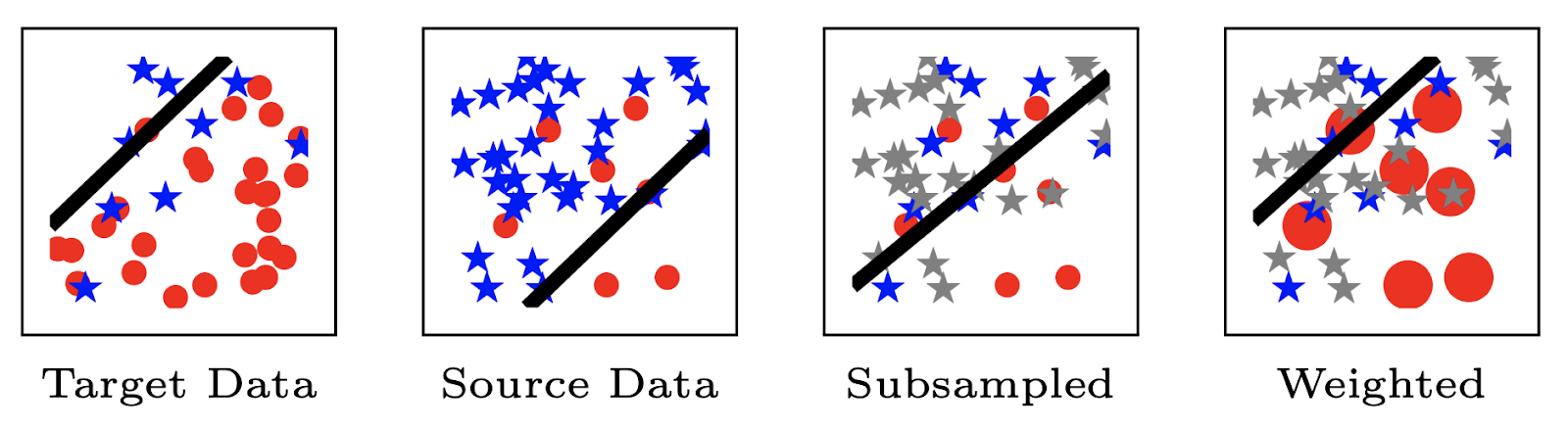
It is common to have imbalanced training datasets where certain attributes (e.g. darker skin tone) are not well represented. We tackle a general framework that can handle any arbitrary distributional shift in the label proportions between training and testing data. Simple approaches to handle label shift involve class balanced sampling or incorporating importance weights. However, we show that neither is optimal. We proposal a new method that optimally combines these methods and balances the bias introduced from class-balanced sampling and the variance due to importance weighting. Paper
In the next post, I will be highlighting some important contributions to optimization methods.
5 thoughts on “2020 AI Research Highlights: Handling distributional shifts (part 2)”