Embodied AI is the union of “mind” (AI) and “body” (robotics). To achieve this, we need robust learning methods that can be embedded into control systems with safety and stability guarantees. Many of our recent works are advancing these goals on both theoretical and practical fronts.
This is part of the blog series on 2020 research highlights. You can read other posts for research highlights on generalizable AI (part 1), handling distributional shifts (part 2), optimization for deep learning (part 3), AI4science (part 4), controllable generation (part 5).
Safe Exploration and Planning
My journey into this area of learning and control started with the neural lander. We used deep learning to learn the aerodynamic ground effects in drones. This led to improved landing speed without sacrificing stability requirements. In a subsequent work, we aimed to automate the collection of drone data while staying safe.
We employed robust regression methods with guaranteed uncertainty bounds that guarantees safety even outside of the training domain. This allows the drone to progressively land faster while maintaining safety (i.e. not crashing). Our method trains a density-ratio estimator that accurately predicts the ability to maintain safety at higher speeds. This is based on the principle of adversarial risk minimization, that has also shown gains in sim-to-real generalization in computer vision (post 2).
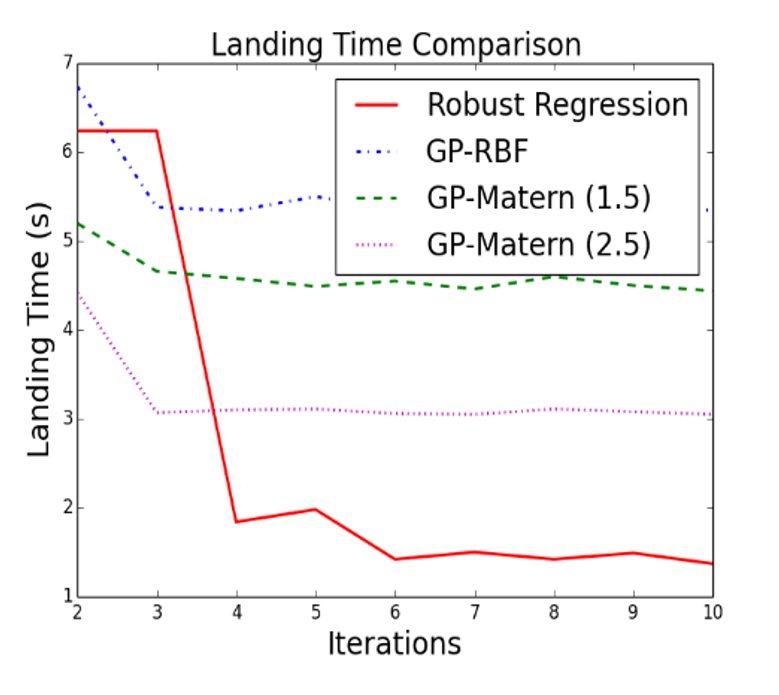
We employed our method on a simulator, built with data collected from real drones. Our method is superior to popular Gaussian process (GP) method for uncertainty quantification and leads to faster exploration while maintaining safety. This is because GPs are brittle in high dimensions due to poor choice of kernels/priors.
The ability to explore safely can now be combined with downstream trajectory planning methods in control. It allows us to propagate uncertainty bounds from robust regression and we pose it as chance constraints for planning methods. Thus, we can compute a pool of safe and information-rich trajectories.

The episodic learning framework is applied to the robotic spacecraft model to explore the state space and learn the friction under collision constraints. We show a significant reduction in variance of the learned model predictions and the number of collisions using robust regression models.
Reinforcement learning in control systems
Analyzing RL in control systems is challenging due to the following reasons: (1) state and action spaces are continuous (2) safety and stability requirements (3) partial observability.
A canonical setting is the linear quadratic Gaussian (LQG) that involves linear dynamics evolution and linear transformation of the hidden state to yield observations with Gaussian noise. LQG appears deceptively simple, but is notoriously challenging to analyze.
Previous methods focused on open loop control which uses random excitation (i.e. actions) to collect measurements for model estimation. However, this yields a regret of T^0.66 which is not optimal, where T is the number of time steps. Paper

Our method is the first closed-loop RL method with guaranteed regret bounds. In closed-loop control, the past measurements are all correlated with the control actions which makes it challenging to estimate the model parameters. We utilize tools from classical control theory (predictive form) to guarantee consistent estimation of the model parameters. This yields an improved regret bound of T^0.5. Paper
Surprisingly, we can do better in terms of the regret bound. We showed that combining online learning with episodic updates can lead to logarithmic regret. Intuitively, we decouple adaptive learning of model parameters (episodic updates) with online learning of control policy. This combination allows us to achieve fast learning (with low regret) in closed-loop control. Paper
3 thoughts on “2020 AI Research Highlights: Learning and Control (part 6)”