In this post, I will focus on the new optimization methods we proposed in 2020. Simple gradient-based methods such as SGD and Adam remain the “workhorses” for training standard neural networks. However, we find many instances where more sophisticated and principled approaches beat these baselines and show promising results.
You can read previous posts for other research highlights: generalizable AI (part 1), handling distributional shifts (part 2), AI4science (part 4), controllable generation (part 5), learning and control (part 6), learning framework (part 7).
Low-Precision Training
Employing standard optimization techniques such as SGD and Adam for training in low precision systems leads to severe degradation as the bit width is reduced. Instead, we propose a co-design framework where we jointly design the bit representation and optimization algorithm.
We draw inspiration from how our own brains represent information: there is strong evidence that it uses a logarithmic number system. This system can efficiently handle a large dynamic range even with low bitwidth. We propose a new optimization method MADAM for directly optimizing in the logarithmic number system. This is a multiplicative weight update version of the popular Adam method. We show that it obtains state-of-art performance in low bitwidth training, often without any learning rate tuning. Thus, Madam can directly train compressed neural networks where the weights are efficiently represented in a logarithmic number system. Paper

Competitive optimization
This extends single-agent optimization to multiple agents with their own objective functions. It has applications ranging from constrained optimization to generative adversarial networks (GANs) and multi-agent reinforcement learning (MARL).
We introduce competitive gradient descent (CGD) as a natural generalization of gradient descent (GD). In GD, each agent updates based on their own gradients, and there is no interaction among the players. In contrast, CGD incorporates interactions among the players by posing it as the Nash equilibrium of a local bilinear approximation of their objectives. This reduces to having a preconditioner based on the mixed Hessian function. This is efficient to implement using conjugate gradient (CG) updates. We see that CGD successfully converges in all instances of games where GD is unstable and exhibits oscillatory behavior. Blog
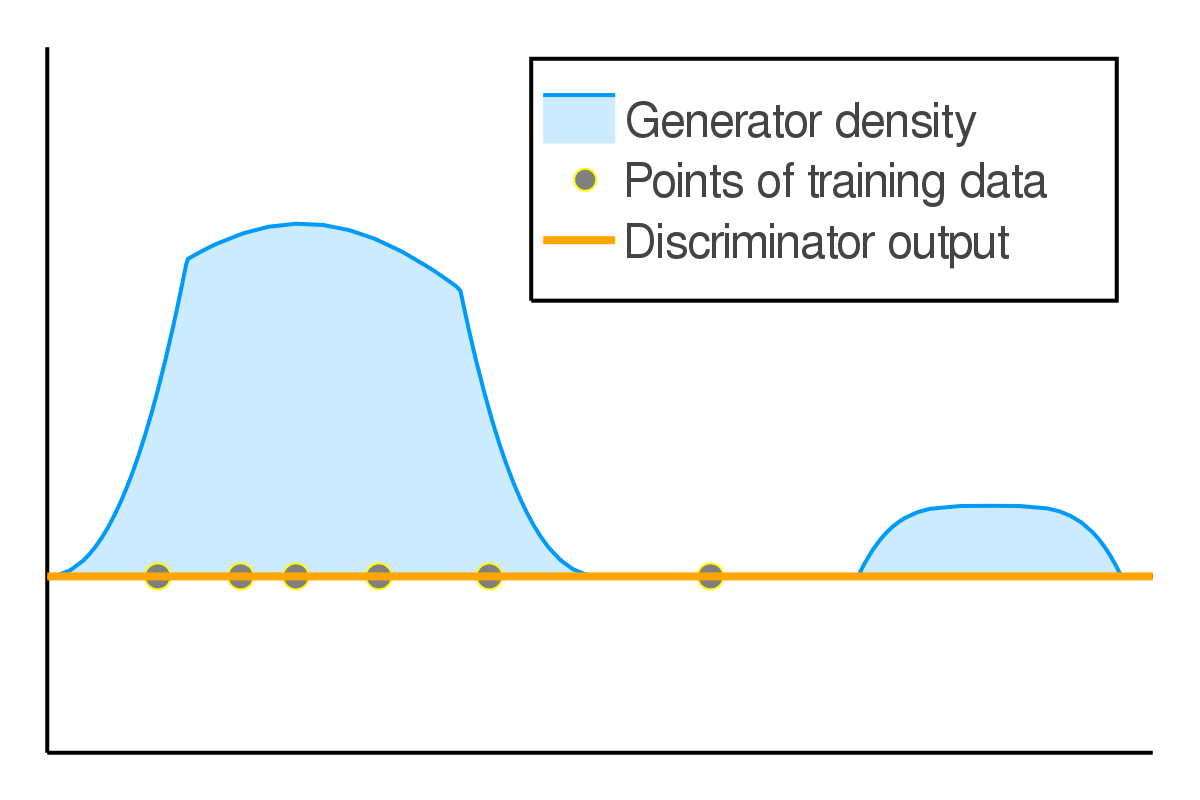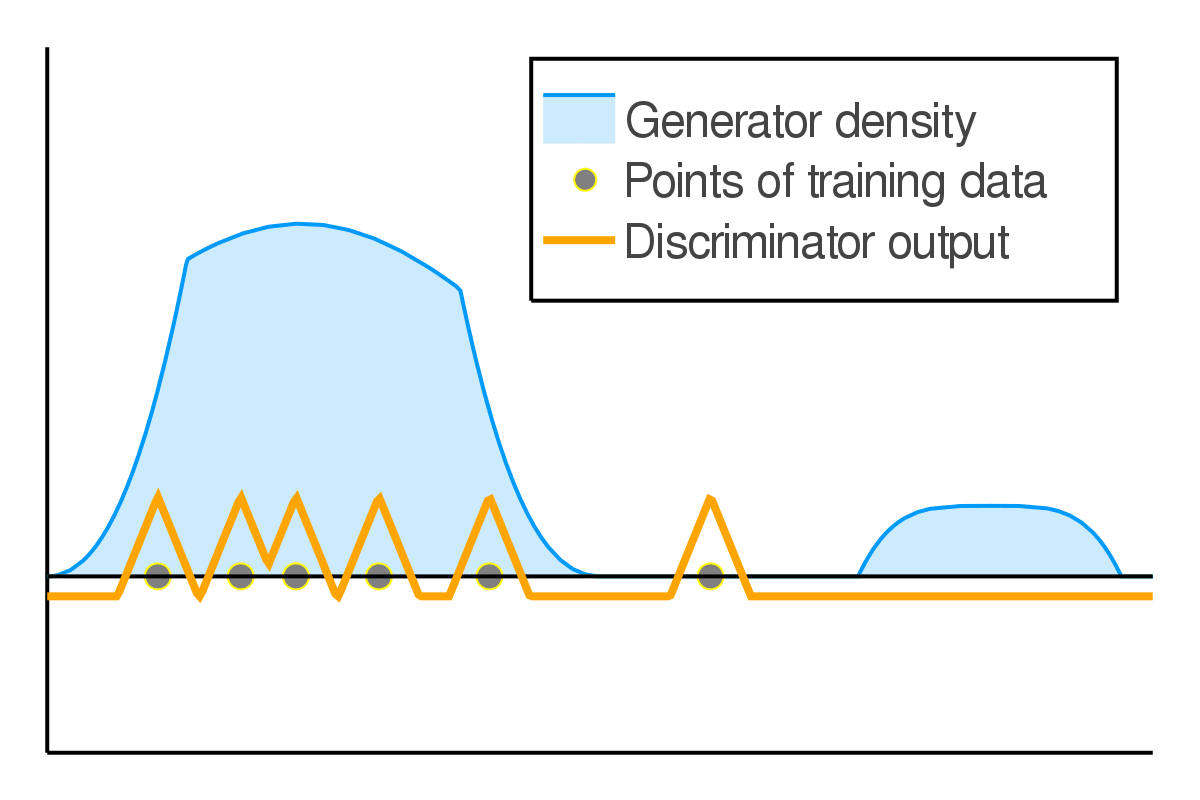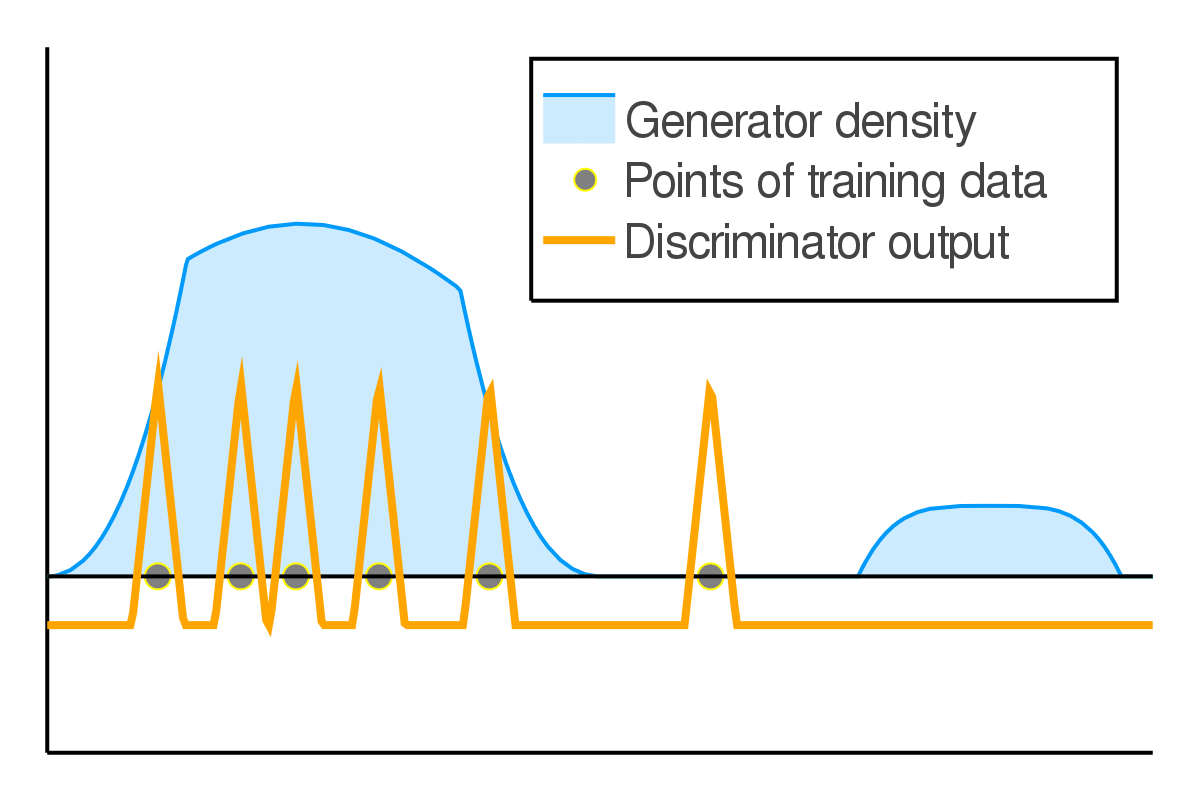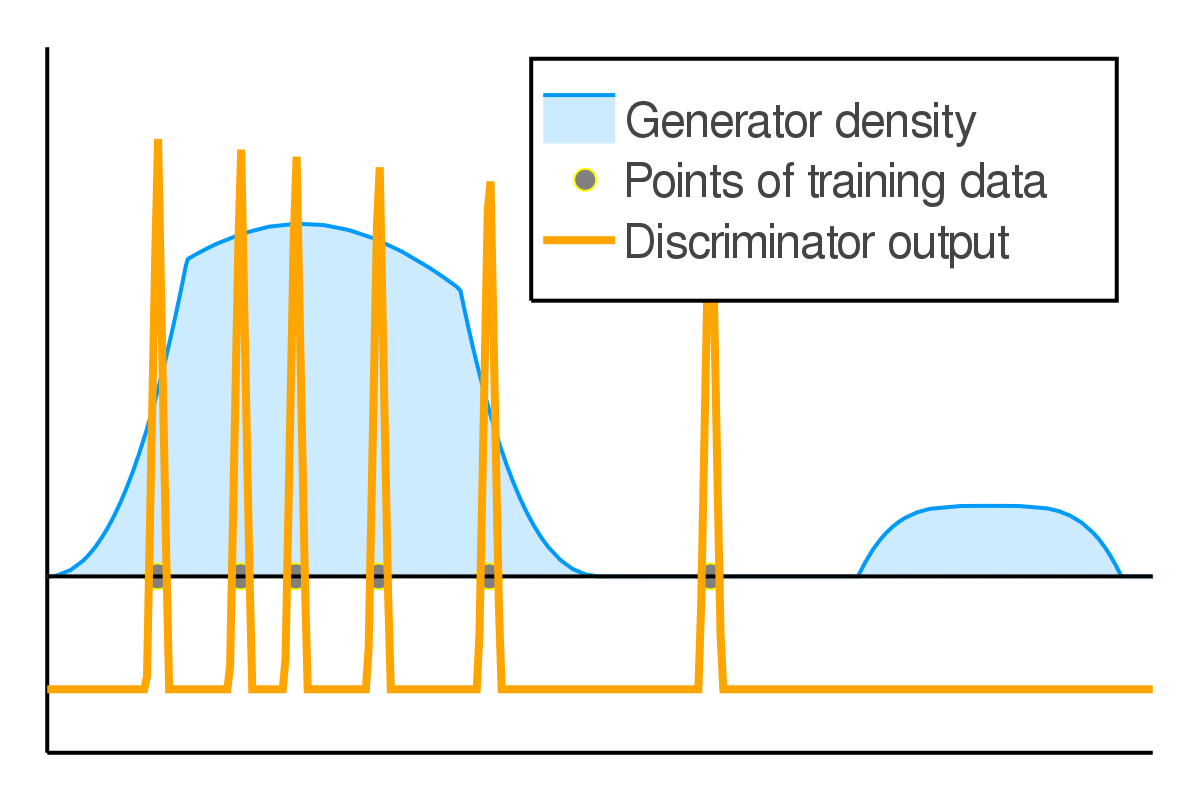
We further used the game-theoretic intuitions CGD to study dynamics in GAN training. There is a delicate balance between generator and discriminator capabilities to obtain the best performance. If the discriminator becomes too powerful on the training data, it will reject all samples outside of training leading to pathological solutions. We show that this pathology is prevented due to simultaneous training of both agents, and we term this as implicit competitive regularization (ICR). We observe that CGD strengthens ICR and prevents oscillatory behavior, and thus improves GAN training. Blog

Stay tuned for more!
2 thoughts on “2020 AI Research Highlights: Optimization for Deep Learning (part 3)”