Generative models have greatly advanced over the last few years. We can now generate images and text that pass the Turing test: at the first glance, they look considerably realistic.
A major unsolved challenge is the ability to control the generative process. We would like specify attributes or style codes for image generation; we would like to shape the narrative of text generation. We have made progress with both these goals and will describe them in this post.
You can read previous posts for other research highlights: generalizable AI (part 1), handling distributional shifts (part 2), optimization for deep learning (part 3), AI4science (part 4), learning and control (part 6), learning framework (part 7).
Controllable Text Generation: Megatron-CTRL
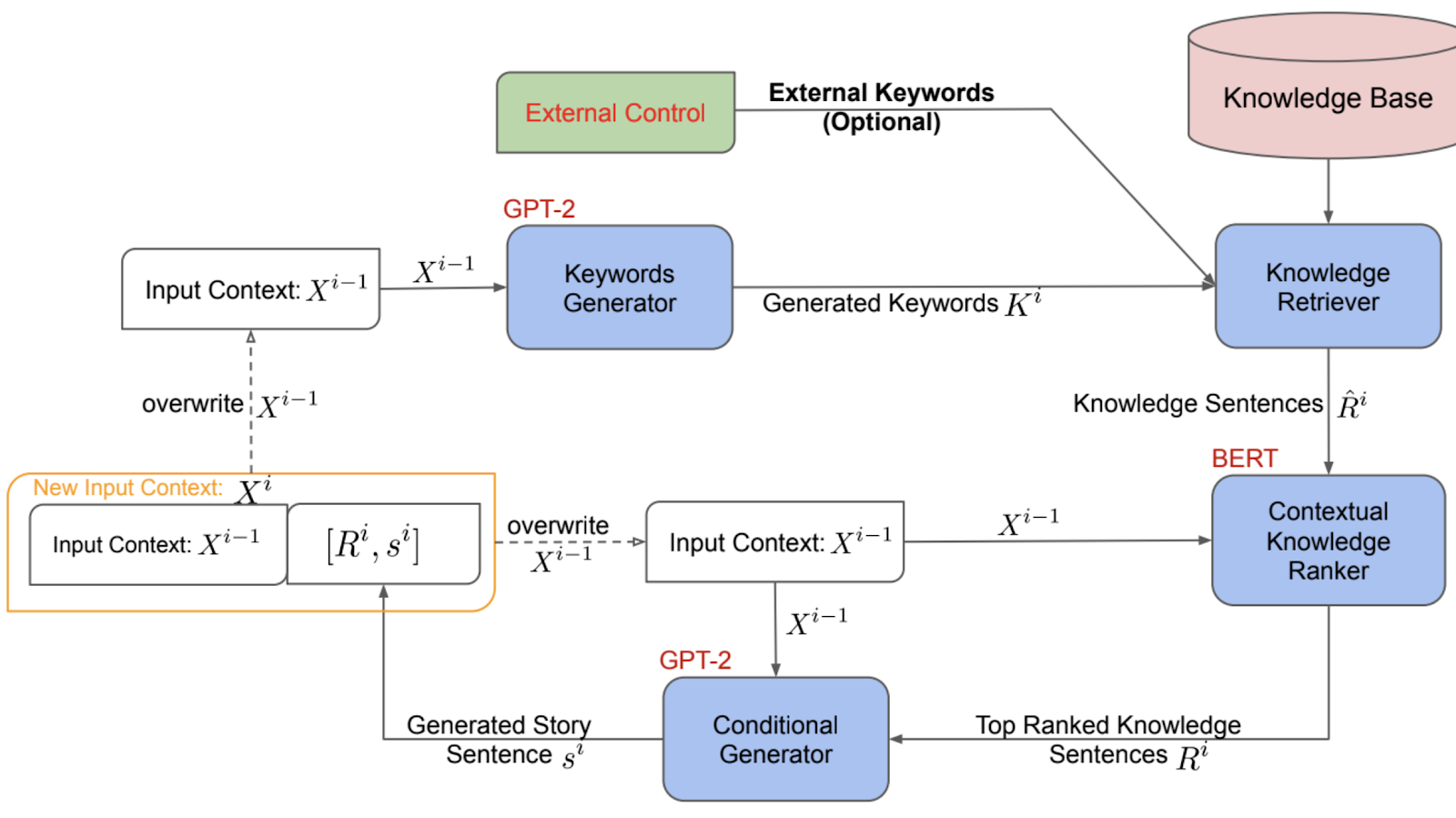
Large pretrained language models like GPT can generate long paragraphs of text. However, these models are uncontrollable and make mistakes like common-sense errors, repetition, and inconsistency. In a recent paper, we add ability to dynamically control text generation using keywords and it also incorporates an external knowledge base. Our framework consists of a keyword generator, a knowledge retriever, a contextual knowledge ranker, and a conditional text generator. Results show that our model generates more fluent, consistent, and coherent stories with less repetition and higher diversity. Paper Slides

Disentanglement Learning in StyleGAN
Disentanglement learning is crucial for obtaining disentangled representations and controllable generation. Current disentanglement methods face several inherent limitations: difficulty with high-resolution images, primarily on learning disentangled representations, and non-identifiability due to the unsupervised setting. To alleviate these limitations, we design new architectures and loss functions based on StyleGAN (Karras et al., 2019), for semi-supervised high-resolution disentanglement learning.
We create two complex high-resolution synthetic datasets for systematic testing. We investigate the impact of limited supervision and find that using only 0.25%~2.5% of labeled data is sufficient for good disentanglement on both synthetic and real datasets.
We propose new metrics to quantify generator controllability, and observe there may exist a crucial trade-off between disentangled representation learning and controllable generation. We also consider semantic fine-grained image editing to achieve better generalization to unseen images. Project page


There is still more to come!
You must be logged in to post a comment.